MONET: Lowering the bar for World-Class Image Generation research.










Together, these give researchers everything they need to train production-grade text-to-image models without the prohibitive cost and complexity that has long gatekept the field.

Resources
- Project page: github/gojasper/monet
- nano-t2i: github/gojasper/nano-t2i
- Dataset: HF/jasperai/monet
- Monet Retrieval: HF/jasperai/monet-retrieval
- Paper: MONET: A Massive, Open, Non-redundant and Enriched Text-to-image Dataset

The Problem: A Data Gap Holding Back Text to Image research
AI image generators like DALL-E, Stable Diffusion, and Midjourney can conjure almost anything from a text description. But training these models requires enormous collections of high-quality images paired with detailed descriptions. Building such a collection is expensive and time-consuming.
Until now, that meant only a handful of well-resourced AI labs could train truly competitive image models. Existing open datasets like LAION-5B were huge but messy: full of duplicates, low-quality images, harmful content, and short, uninformative captions scraped from the web. More curated alternatives existed but were either too small for serious pre-training or kept proprietary.
Reproducibility gap. Academic researchers and smaller companies couldn't train models that matched closed-source commercial systems. Not because the techniques were secret, but because the training data was.
MONET bridges this gap. It's the first openly released, filtered, deduplicated, and multi-captioned dataset designed specifically for pre-training large text-to-image models at scale. It's free to use for commercial purposes under the Apache 2.0 license.
The Curation Pipeline: From 2.9 Billion URLs to 104.9 Million High-Quality Images
Think of MONET as a giant filtering funnel. The team started with essentially the entire open internet's image collection and ran it through six carefully designed stages to keep only the best.
The challenge? Every filtering decision involves trade-offs. Be too strict and you lose rare, valuable images. Be too lenient and you pollute the dataset with junk that degrades model quality.
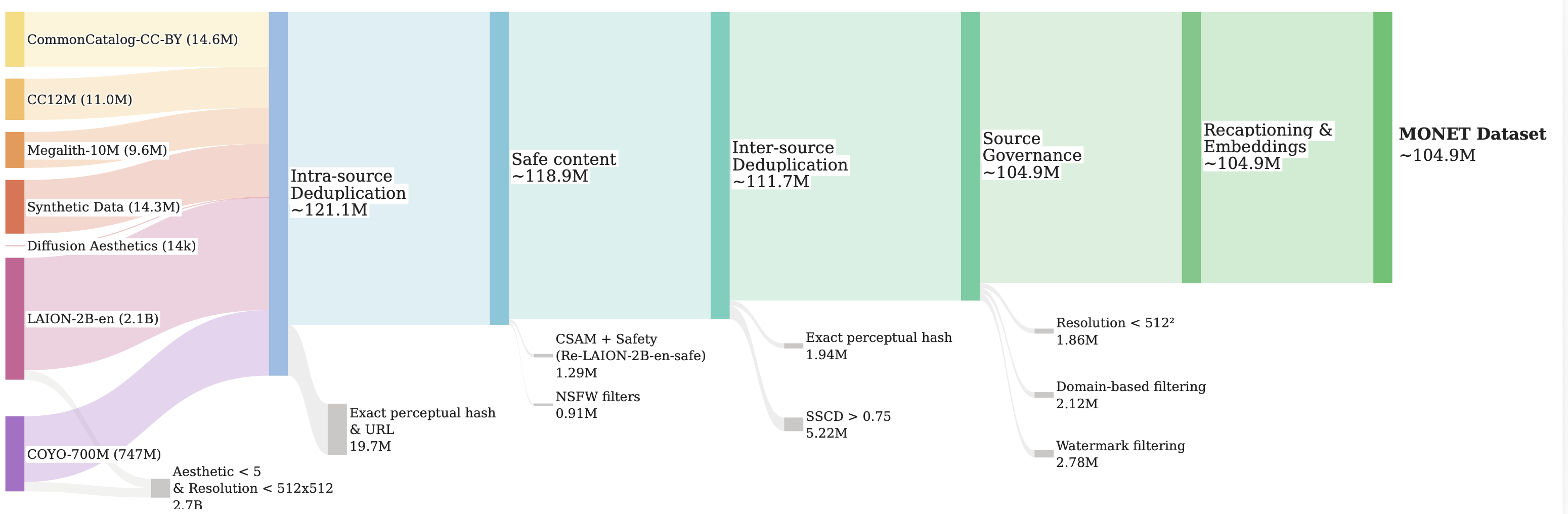
Stage 1: Aesthetic Pre-filtering: The two largest sources (LAION and COYO) are prescreened before the main pipeline. Any image smaller than 512×512 pixels or scoring below 5.0 on an aesthetic quality scale is discarded immediately. This concentrates computational resources on images that are at least potentially useful, cutting the combined pool from ~2.85B down to ~121M before the merge.
Stage 2: Safety Filtering: Web images can contain harmful content. MONET uses a union ensemble of three independent Not-Safe-For-Work classifiers. If any one of them flags an image, it's removed. The LAION source is also restricted to the already-vetted Re-LAION safe release. A final audit using image similarity search found no remaining harmful clusters. This stage removes only 1.8% of images (it was already mostly safe after pre-filtering) but provides critical safety coverage.
Stage 3: Deduplication: Duplicate images are a major problem in web-scraped data. If a model sees the same image thousands of times, it overfits to that image and loses generalization. MONET uses a two-stage approach: First, perceptual hashing catches exact or near-exact copies (same image, different compression). Then, SSCD embeddings, a specialized "copy detection" AI, catches near-duplicates like cropped versions, color-shifted copies, or images with added watermarks. Together these remove over 26 million duplicate images while keeping images that are merely similar but genuinely different.
Stage 4: Domain Filtering & Governance: The final cleanup removes images from known stock-photo providers (Getty, Shutterstock, Dreamstime, etc.) and images with visible watermarks.

Content Distribution
To understand the dataset's coverage, the team classified all 104.9M images using CLIP, a model that can match images to text labels without explicit training. The result is a surprisingly balanced distribution across the subjects that matter most for real-world image generation.

MONET dataset distribution: (left) YOLO-based content classification, (middle) CLIP-based content classification, (right) Qwen3-VL-8B-Instruct based image style.
Unlike some image datasets that are dominated by a single category (e.g., mostly product photos or stock imagery), MONET spans a genuine breadth of human visual culture, from street scenes and wildlife to digital art and food. This diversity is what makes it possible to train a general-purpose image model from MONET alone.
Captioning: creating some text for every images.
Here's a counter-intuitive insight from recent AI research: the quality of the text descriptions matters at least as much as the quality of the images themselves. A stunning photograph paired with a vague caption teaches the model much less than a good photo paired with a rich, detailed description.
Original web captions are typically short, noisy alt-text like "photo.jpg" or "beautiful sunset". MONET replaces these with AI-generated descriptions from four different vision-language models (VLMs), each offering a different perspective and level of detail.
Why four captioners instead of one? Using a single AI to describe everything creates blind spots. Mix multiple captioners and you get more robust, varied descriptions that generalize better to user prompts.

Every image in MONET ships with up to five captions: the original web caption plus one from each of the four VLMs. During training, a caption is sampled randomly, exposing the model to the full range of prompt styles it will encounter in the real world.
Adding synthetic data
One of MONET's most interesting design decisions is mixing real and AI-generated images. Synthetic data can fill coverage gaps and improve alignment while but too much creates problems.
The team ran a systematic experiment: train the same image model with varying proportions of synthetic data and measure quality using the FID score (Fréchet Inception Distance ; lower means more realistic images). The results reveal a clear optimum around the 50% mark (lower FID = better quality).

The catastrophic jump at 100% synthetic ((\text{FID} = 15.0) vs. (\sim 7\text{–}8) for real-data mixtures) illustrates the "AI eating itself" problem: when a model trains only on images generated by other AI models, quality degrades rapidly as errors amplify through the feedback loop.
MONET's 13% synthetic ratio sits comfortably in the beneficial zone, improving text-image alignment without incurring the risks of synthetic data saturation.
Validation
All this curation work is only valuable if it actually produces better AI models. To validate MONET, the team trained a 4-billion-parameter image model exclusively on this dataset and measured it against existing commercial and research models.

The results on GenEval — a benchmark that tests whether a model can accurately depict objects, colors, counts, and spatial relationships described in a prompt — are striking. MONET's 4B model outperforms much larger models like DALL-E 3 and FLUX.1 Dev (12B parameters), despite training exclusively on open data.

A 4.1B MONET model scores 0.74 on GenEval and 85.56 on DPG — competitive with models 3–5× its size trained on closed, proprietary datasets. This demonstrates that data quality and curation matter more than raw data scale.
On the DPG benchmark (which tests longer, more complex prompts), MONET's model is similarly competitive, ranking above DALL-E 3, SD3, and FLUX.1 Dev — systems backed by enormous research teams and confidential training data. The remaining gap with the very largest models (Qwen-Image at 20B, Z-Image at 6B) is largely attributable to parameter count and likely additional fine-tuning data, not MONET's intrinsic quality.
Limitations
Geographic & Cultural Bias: MONET inherits the Western bias of Common Crawl-based sources. European and North American contexts are over-represented. Skin tones skew toward Fitzpatrick 3–4. This is a known limitation of web-scraped data that future work aims to address through balanced sampling and multilingual expansion.
English-Only Captions: All captions are in English. Multilingual image generation and cross-lingual retrieval would require translation pipelines or multilingual captioners — an obvious and planned extension.
Caption Hallucinations: AI captioners sometimes fabricate details not visible in the image. Multiple captioners partially mitigate this (hallucinations are unlikely to be consistent across models), but some errors persist. There is no fully automated way to verify caption accuracy at 100M-image scale.
Safety Coverage: No filtering pipeline is perfect. The conservative approach may have removed some safe images while potentially missing some harmful ones. The team recommends adding output-level safety classifiers for any deployed application.
Training Your Own Model with nano-t2i
nano-t2i is a minimal text-to-image diffusion training repository built specifically for the MONET dataset. If you want to go from dataset to a working T2I model without wading through a large codebase, this is the fastest path.
The codebase makes it super easy to get started:
# Clone the repo
git clone https://github.com/gojasper/nano-t2i.git
cd nano-t2i
# Install dependencies
uv venv envs/nano-t2i --python 3.13
source envs/nano-t2i/bin/activate
uv pip install -e ".[training]"
# Launch the training
python examples/trainings/training.py examples/trainings/configs/t2i/nano.yaml
Training time: roughly ~1 day on a single H200 to get good results, or ~3 hours on 8× H200s to reach similar quality.
Conclusion
Open research thrives on shared foundations. MONET and nano-t2i are Jasper Research's contribution to that foundation. A carefully curated, commercially licensed dataset and a minimal training codebase that together remove the two biggest barriers to competitive text-to-image research: data and complexity.
Jasper Research
Blog post written May 2026.