Uploaded as 16bit model
- Developed by: Labagaite
- License: apache-2.0
- Finetuned from model : unsloth/gemma-2b-it-bnb-4bit
Training Logs
Traning metrics
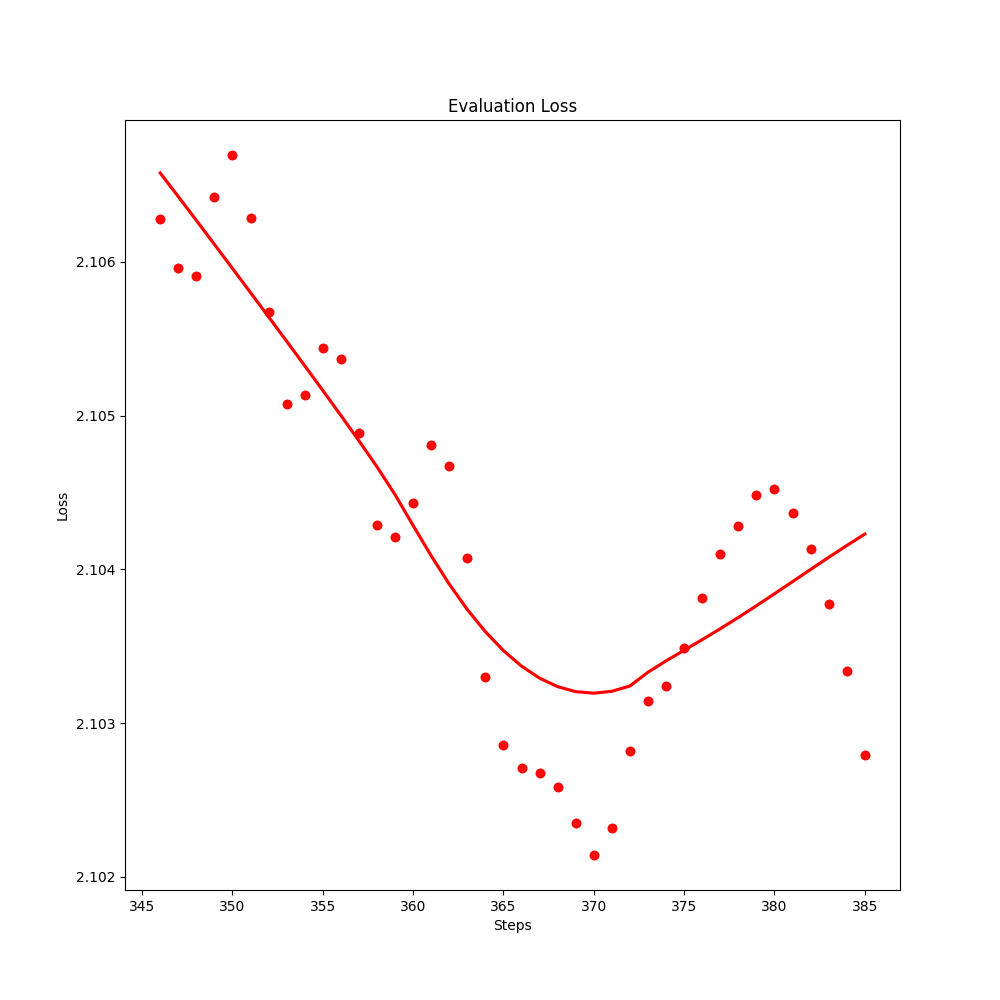
Evaluation score
Évaluation du rapport généré par le modèle unsloth/gemma-2b-it-bnb-4bit :
Performance de la structuration du rapport : 6/10
- Le rapport est bien structuré en chapitres distincts, mais certains points pourraient être mieux développés et organisés.
Qualité du langage : 7/10
- Le langage utilisé est formel et professionnel, mais il manque parfois de fluidité et de clarté dans l'expression des idées.
Cohérence : 6/10
- La cohérence entre les différents chapitres est présente, mais il y a des transitions abruptes et des lacunes dans certaines explications.
Évaluation du rapport généré par le modèle gemma-Summarizer-2b-it-bnb-4bit :
Performance de la structuration du rapport : 8/10
- Le rapport est bien structuré en sections claires et précises, facilitant la lecture et la compréhension.
Qualité du langage : 8/10
- Le langage utilisé est riche et varié, offrant une lecture agréable et captivante pour le lecteur.
Cohérence : 7/10
- La cohérence entre les différentes parties du rapport est bonne, mais certaines transitions pourraient être améliorées pour une meilleure fluidité.
Score global :
- Modèle unsloth/gemma-2b-it-bnb-4bit : 6.3/10
- Modèle gemma-Summarizer-2b-it-bnb-4bit : 7.7/10
Conclusion :
Le modèle gemma-Summarizer-2b-it-bnb-4bit obtient un score global plus élevé que le modèle unsloth/gemma-2b-it-bnb-4bit en raison de sa meilleure structuration, de la qualité supérieure du langage utilisé et d'une cohérence globale plus solide. Le rapport généré par le modèle gemma-Summarizer-2b-it-bnb-4bit est plus complet, captivant et bien organisé, ce qui en fait un choix préférable pour la génération de rapports détaillés et professionnels.
Evaluation report and scoring
Wandb logs
You can view the training logs  .
.
Training details
training data
- Dataset : fr-summarizer-dataset
- Data-size : 7.65 MB
- train : 1.97k rows
- validation : 440 rows
- roles : user , assistant
- Format chatml "role": "role", "content": "content", "user": "user", "assistant": "assistant"
*French audio podcast transcription*
Project details
 Fine-tuned on French audio podcast transcription data for summarization task. As a result, the model is able to summarize French audio podcast transcription data.
The model will be used for an AI application: Report Maker wich is a powerful tool designed to automate the process of transcribing and summarizing meetings.
It leverages state-of-the-art machine learning models to provide detailed and accurate reports.
Fine-tuned on French audio podcast transcription data for summarization task. As a result, the model is able to summarize French audio podcast transcription data.
The model will be used for an AI application: Report Maker wich is a powerful tool designed to automate the process of transcribing and summarizing meetings.
It leverages state-of-the-art machine learning models to provide detailed and accurate reports.
This gemma model was trained 2x faster with Unsloth and Huggingface's TRL library.
This gemma was trained with LLM summarizer trainer
 LLM summarizer trainer
LLM summarizer trainer


{kind=link}
