
Zero-Shot classification
Collection
Collection of zero shot classification models based on Gliznet architecture • 3 items • Updated
GliZNet (Generalized Zero-Shot Network) is a zero-shot text classification model that processes the input text and all candidate labels jointly in a single forward pass, achieving O(1) inference complexity regardless of the number of labels.
Available in two backbone variants:
GliZNet encodes text and labels together in one sequence, extracts each label's representation from its [LAB] separator token, builds a label-specific text summary via cross-attention, and scores each pair with a bilinear head. A hybrid loss combining one-vs-negatives softmax (primary, with additive margin), auxiliary focal loss, and a partial VICReg regularizer (variance + covariance terms only — the invariance term is dropped, leaving a pure label-repulsion objective) sharpens discrimination between semantically similar labels.
Paper: GliZNet: A Novel Architecture for Zero-Shot Text Classification Alex Kameni (Ivalua / Massy, France)
Code: github.com/KameniAlexNea/zero-shot-classification Synthetic data generation: github.com/KameniAlexNea/generate-gliznet-data
| Property | Value |
|---|---|
| Backbone | microsoft/deberta-v3-base (answerdotai/ModernBERT-base ( |
| Scoring head | Bilinear (nn.Bilinear(D, D, 1)) |
| Max sequence length | 512 tokens |
| Label separator token | [LAB] |
| Label representation | [LAB] token hidden state |
| Training precision | bfloat16 |
| Model type ID | gliznet |
flowchart TD
A["Input sequence\n[CLS] <text> [SEP] <label_1> [LAB] <label_2> [LAB] … [PAD]"]
A --> B["DeBERTa-v3-base\nContextual hidden states"]
B --> C["Label repr\n[LAB] token hidden state per label"]
B --> D["Label-specific text repr\nCross-attention: label queries text tokens"]
C --> E["Bilinear scoring head\nlogit = Bilinear(text_repr, label_repr)"]
D --> E
E --> F["One-vs-negatives loss (+ margin)\n+ focal loss\n+ label repulsion\n(training only)"]
ZeroShotClassificationPipeline
import torch
from gliznet.model import GliZNetForSequenceClassification
from gliznet.tokenizer import GliZNETTokenizer
from gliznet.predictor import ZeroShotClassificationPipeline
model = GliZNetForSequenceClassification.from_pretrained("alexneakameni/gliznet-deberta-v3-base")
model = model.to(torch.bfloat16)
tokenizer = GliZNETTokenizer.from_pretrained("alexneakameni/gliznet-deberta-v3-base")
pipeline = ZeroShotClassificationPipeline(
model, tokenizer,
classification_type="multi-label", # or "multi-class"
device="cuda",
)
text = "Scientists discover a new exoplanet orbiting a distant star."
labels = ["astronomy", "politics", "cooking", "space exploration", "finance"]
result = pipeline(text, labels)
for ls in sorted(result.labels, key=lambda x: -x.score):
print(f" {ls.label:<25} {ls.score:.3f}")
from_pretrained + HuggingFace AutoModel
from transformers import AutoModel, AutoConfig
import gliznet # triggers Auto* registration
config = AutoConfig.from_pretrained("alexneakameni/gliznet-deberta-v3-base")
model = AutoModel.from_pretrained("alexneakameni/gliznet-deberta-v3-base")
Evaluated on the GLiClass benchmark — 10 standard text-classification datasets reported as macro F1. GLiClass variants are the closest published competitors; all encode text and labels jointly in a single forward pass.
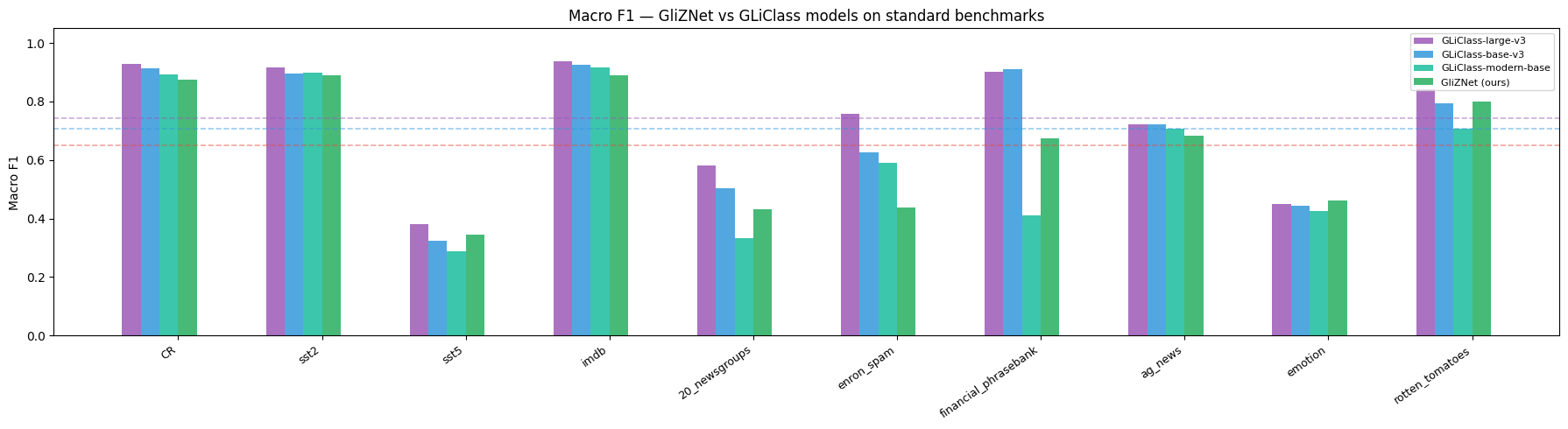
| Dataset | GliZNet ModernBERT-Base (ours) | GliZNet DeBERTa-v3-Base (ours) | GLiClass-large-v3 | GLiClass-base-v3 | GLiClass-modern-base |
|---|---|---|---|---|---|
| CR | 0.8902 | 0.9001 | 0.9281 | 0.9127 | 0.8936 |
| SST-2 | 0.8710 | 0.8858 | 0.9176 | 0.8959 | 0.8982 |
| SST-5 | 0.4227 | 0.3387 | 0.3798 | 0.3236 | 0.2885 |
| IMDb | 0.8866 | 0.9037 | 0.9366 | 0.9248 | 0.9154 |
| 20-Newsgroups | 0.3981 | 0.4862 | 0.5806 | 0.5045 | 0.3342 |
| Enron Spam | 0.4317 | 0.5892 | 0.7574 | 0.6252 | 0.5903 |
| Financial PhraseBank | 0.8037 | 0.7970 | 0.9023 | 0.9094 | 0.4121 |
| AG News | 0.7800 | 0.7384 | 0.7229 | 0.7209 | 0.7069 |
| Emotion | 0.4042 | 0.5135 | 0.4504 | 0.4450 | 0.4249 |
| Rotten Tomatoes | 0.7456 | 0.7357 | 0.8411 | 0.7943 | 0.7060 |
| AVERAGE | 0.6634 | 0.6888 | 0.7417 | 0.7056 | 0.6170 |
Δ GliZNet-ModernBERT vs GLiClass-large: −0.0783 · Δ vs GLiClass-base: −0.0422 · Δ vs GLiClass-modern-base: +0.0464 Δ GliZNet-DeBERTa vs GLiClass-large: −0.0529 · Δ vs GLiClass-base: −0.0168 · Δ vs GLiClass-modern-base: +0.0718
Both GliZNet variants are base-size models trained on synthetic data with a single-stage pipeline. GliZNet-DeBERTa surpasses GLiClass-base on AG News, Emotion, and SST-5. GliZNet-ModernBERT excels on SST-5 (+0.0991 vs GLiClass-base) and AG News (+0.0591).
| Setting | Value |
|---|---|
| Dataset | alexneakameni/ZSHOT-HARDSET-v2 (train split) + alexneakameni/eval-zero-shot-classification (test) |
| Additional datasets | 14 MCQ / NLI datasets (1k samples each) |
| Optimizer | AdamW |
| Learning rate | 1e-5 (cosine schedule, 5% warmup) |
| Weight decay | 1e-3 |
| Batch size | 48 × 2 GPUs × 2 grad. accum. = 192 effective |
| Epochs | 10 (early stopping, patience=3) |
| Precision | bf16 |
| Distributed training | DDP via accelerate launch |
| Hardware | 2 × NVIDIA GPU |
| Loss | One-vs-negatives softmax (weight 0.8, margin 0.25) + focal loss (weight 1.2, γ=1.85, adaptive γ=0 for pure-class samples, class-balanced averaging) + label repulsion (weight 0.4) + alignment loss (weight 0.2, cosine embedding loss with margin=0.2, asymmetric weighting) |
| Max labels per sample | 20 |
| Label enrichment | LabelContextAttention: each label attends to peers + their first-pass text evidence (cooperative routing) |
| Text augmentation | nlpaug pipeline (keyboard typos, OCR typos, char swap/delete, word delete, spelling errors, suffix truncation, case change) |
| Label augmentation | ScenarioAwareSampler: needle 20%, few_pos 15%, few_neg 10%, balanced 10%, passthrough 45%. Count sampled via triangular distribution biased toward max. |
GliZNETTokenizer wraps the DeBERTa-v3 sentencepiece tokenizer and adds a custom [LAB] separator token. The input format is:
[CLS] <text> [SEP] <label_1> [LAB] <label_2> [LAB] ... <label_n> [LAB] [PAD]*
The lmask tensor (label mask) assigns 0 to text tokens and unique integers 1…n to each label's tokens, allowing the model to pool each label independently.
@article{kameni2025gliznet,
title = {GliZNet: A Novel Architecture for Zero-Shot Text Classification},
author = {Alex Kameni},
year = {2025},
note = {Preprint. Code: https://github.com/KameniAlexNea/zero-shot-classification}
}
Apache 2.0
Base model
microsoft/deberta-v3-base