
RacketVision: A Multiple Racket Sports Benchmark for Unified Ball and Racket Analysis
Paper • 2511.17045 • Published
Error code: DatasetGenerationError
Exception: ArrowInvalid
Message: JSON parse error: Invalid value. in row 0
Traceback: Traceback (most recent call last):
File "/usr/local/lib/python3.12/site-packages/datasets/packaged_modules/json/json.py", line 270, in _generate_tables
df = pandas_read_json(f)
^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/site-packages/datasets/packaged_modules/json/json.py", line 34, in pandas_read_json
return pd.read_json(path_or_buf, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/site-packages/pandas/io/json/_json.py", line 815, in read_json
return json_reader.read()
^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/site-packages/pandas/io/json/_json.py", line 1014, in read
obj = self._get_object_parser(self.data)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/site-packages/pandas/io/json/_json.py", line 1040, in _get_object_parser
obj = FrameParser(json, **kwargs).parse()
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/site-packages/pandas/io/json/_json.py", line 1176, in parse
self._parse()
File "/usr/local/lib/python3.12/site-packages/pandas/io/json/_json.py", line 1391, in _parse
self.obj = DataFrame(
^^^^^^^^^^
File "/usr/local/lib/python3.12/site-packages/pandas/core/frame.py", line 778, in __init__
mgr = dict_to_mgr(data, index, columns, dtype=dtype, copy=copy, typ=manager)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/site-packages/pandas/core/internals/construction.py", line 503, in dict_to_mgr
return arrays_to_mgr(arrays, columns, index, dtype=dtype, typ=typ, consolidate=copy)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/site-packages/pandas/core/internals/construction.py", line 114, in arrays_to_mgr
index = _extract_index(arrays)
^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/site-packages/pandas/core/internals/construction.py", line 677, in _extract_index
raise ValueError("All arrays must be of the same length")
ValueError: All arrays must be of the same length
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/local/lib/python3.12/site-packages/datasets/builder.py", line 1872, in _prepare_split_single
for key, table in generator:
^^^^^^^^^
File "/src/services/worker/src/worker/job_runners/config/parquet_and_info.py", line 609, in wrapped
for item in generator(*args, **kwargs):
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/site-packages/datasets/packaged_modules/json/json.py", line 273, in _generate_tables
raise e
File "/usr/local/lib/python3.12/site-packages/datasets/packaged_modules/json/json.py", line 236, in _generate_tables
pa_table = paj.read_json(
^^^^^^^^^^^^^^
File "pyarrow/_json.pyx", line 342, in pyarrow._json.read_json
File "pyarrow/error.pxi", line 155, in pyarrow.lib.pyarrow_internal_check_status
File "pyarrow/error.pxi", line 92, in pyarrow.lib.check_status
pyarrow.lib.ArrowInvalid: JSON parse error: Invalid value. in row 0
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/src/services/worker/src/worker/job_runners/config/parquet_and_info.py", line 1342, in compute_config_parquet_and_info_response
parquet_operations, partial, estimated_dataset_info = stream_convert_to_parquet(
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/src/services/worker/src/worker/job_runners/config/parquet_and_info.py", line 907, in stream_convert_to_parquet
builder._prepare_split(split_generator=splits_generators[split], file_format="parquet")
File "/usr/local/lib/python3.12/site-packages/datasets/builder.py", line 1739, in _prepare_split
for job_id, done, content in self._prepare_split_single(
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/site-packages/datasets/builder.py", line 1925, in _prepare_split_single
raise DatasetGenerationError("An error occurred while generating the dataset") from e
datasets.exceptions.DatasetGenerationError: An error occurred while generating the datasetNeed help to make the dataset viewer work? Make sure to review how to configure the dataset viewer, and open a discussion for direct support.
text list |
|---|
[
"match178",
"000"
] |
[
"match179",
"000"
] |
[
"match18",
"000"
] |
[
"match180",
"000"
] |
[
"match181",
"000"
] |
[
"match182",
"000"
] |
[
"match183",
"000"
] |
[
"match184",
"000"
] |
[
"match185",
"000"
] |
[
"match186",
"000"
] |
[
"match187",
"000"
] |
[
"match188",
"000"
] |
[
"match189",
"000"
] |
[
"match19",
"000"
] |
[
"match190",
"000"
] |
[
"match191",
"000"
] |
[
"match192",
"000"
] |
[
"match193",
"000"
] |
[
"match194",
"000"
] |
[
"match195",
"000"
] |
[
"match196",
"000"
] |
[
"match197",
"000"
] |
[
"match198",
"000"
] |
[
"match199",
"000"
] |
[
"match2",
"000"
] |
[
"match20",
"000"
] |
[
"match200",
"000"
] |
[
"match201",
"000"
] |
[
"match202",
"000"
] |
[
"match203",
"000"
] |
[
"match204",
"000"
] |
[
"match205",
"000"
] |
[
"match206",
"000"
] |
[
"match207",
"000"
] |
[
"match208",
"000"
] |
[
"match209",
"000"
] |
[
"match21",
"000"
] |
[
"match210",
"000"
] |
[
"match211",
"000"
] |
[
"match212",
"000"
] |
[
"match213",
"000"
] |
[
"match214",
"000"
] |
[
"match215",
"000"
] |
[
"match216",
"000"
] |
[
"match217",
"000"
] |
[
"match218",
"000"
] |
[
"match219",
"000"
] |
[
"match22",
"000"
] |
[
"match220",
"000"
] |
[
"match221",
"000"
] |
[
"match222",
"000"
] |
[
"match223",
"000"
] |
[
"match224",
"000"
] |
[
"match225",
"000"
] |
[
"match226",
"000"
] |
[
"match227",
"000"
] |
[
"match228",
"000"
] |
[
"match229",
"000"
] |
[
"match23",
"000"
] |
[
"match230",
"000"
] |
[
"match231",
"000"
] |
[
"match232",
"000"
] |
[
"match233",
"000"
] |
[
"match234",
"000"
] |
[
"match235",
"000"
] |
[
"match236",
"000"
] |
[
"match237",
"000"
] |
[
"match238",
"000"
] |
[
"match239",
"000"
] |
[
"match24",
"000"
] |
[
"match240",
"000"
] |
[
"match241",
"000"
] |
[
"match242",
"000"
] |
[
"match243",
"000"
] |
[
"match244",
"000"
] |
[
"match245",
"000"
] |
[
"match246",
"000"
] |
[
"match247",
"000"
] |
[
"match248",
"000"
] |
[
"match249",
"000"
] |
[
"match25",
"000"
] |
[
"match250",
"000"
] |
[
"match251",
"000"
] |
[
"match252",
"000"
] |
[
"match253",
"000"
] |
[
"match254",
"000"
] |
[
"match255",
"000"
] |
[
"match256",
"000"
] |
[
"match257",
"000"
] |
[
"match258",
"000"
] |
[
"match259",
"000"
] |
[
"match26",
"000"
] |
[
"match260",
"000"
] |
[
"match261",
"000"
] |
[
"match262",
"000"
] |
[
"match263",
"000"
] |
[
"match264",
"000"
] |
[
"match265",
"000"
] |
[
"match266",
"000"
] |
[
"match267",
"000"
] |
![]()
![]()
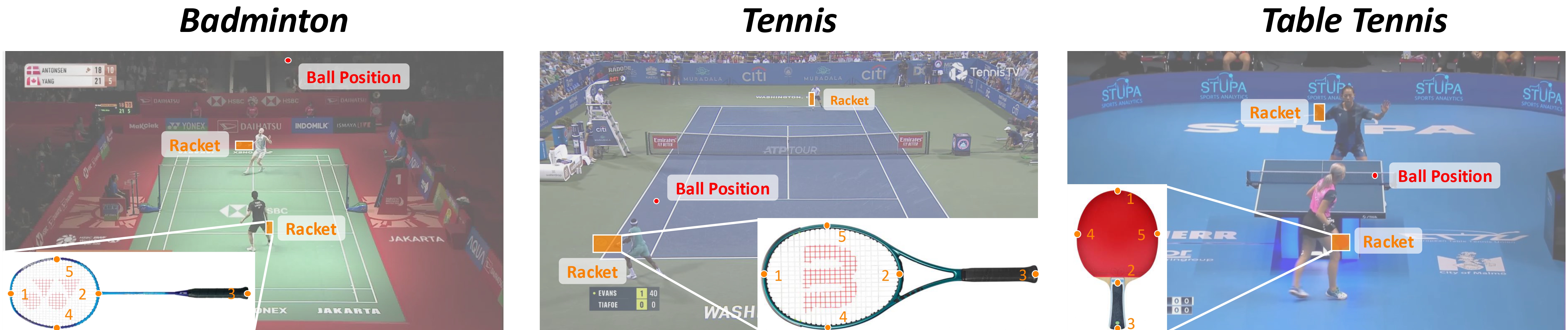
RacketVision is a large-scale, multi-sport dataset and benchmark for advancing computer vision in sports analytics, covering badminton, table tennis, and tennis. It is the first dataset to provide large-scale, fine-grained annotations for racket pose alongside traditional ball positions, enabling research into complex human-object interactions. The benchmark tackles three interconnected tasks: fine-grained ball tracking, articulated racket pose estimation, and predictive ball trajectory forecasting.
This dataset is distributed as static files (videos, CSV, JSON, PKL). Download it with the Hugging Face CLI, then follow the project README for environment setup and training:
# Official code layout (clone https://github.com/OrcustD/RacketVision ): from repo root
hf download linfeng302/RacketVision --repo-type dataset --local-dir source/data
# Stand-alone data folder only (you must point module configs or --data_root to this directory)
hf download linfeng302/RacketVision --repo-type dataset --local-dir data
The in-browser Dataset Viewer may not fully load all assets: COCO detection and pose JSON files use different annotation schemas, so they are not merged into a single datasets-style table. Use the files on disk as documented below.
data/
├── annotations/
│ └── dataset_info.json # Global dataset metadata (clip list, splits)
│
├── info/ # COCO-format annotations for RacketPose
│ ├── train_det_coco.json # Detection: bbox annotations (train split)
│ ├── val_det_coco.json
│ ├── test_det_coco.json
│ ├── train_pose_coco.json # Pose: keypoint annotations (train split)
│ ├── val_pose_coco.json
│ └── test_pose_coco.json
│
├── <sport>/ # badminton / tabletennis / tennis
│ ├── videos/
│ │ └── <match>_<rally>.mp4 # Raw video clips
│ ├── all/
│ │ └── <match>/
│ │ ├── csv/<rally>_ball.csv # Ball ground truth annotations
│ │ └── racket/<rally>/*.json # Racket ground truth annotations
│ ├── interp_ball/ # Interpolated ball trajectories (for rebuilding TrajPred data)
│ ├── merged_racket/ # Merged racket predictions (for rebuilding TrajPred data)
│ └── info/
│ ├── metainfo.json # Sport-specific metadata
│ ├── train.json # [[match_id, rally_id], ...] for training
│ ├── val.json # Validation split
│ └── test.json # Test split
│
└── data_traj/ # Pre-built trajectory prediction datasets
├── ball_racket_<sport>_h20_f5.pkl # Short-horizon: 20 history → 5 future
└── ball_racket_<sport>_h80_f20.pkl # Long-horizon: 80 history → 20 future
Local preprocessing (required for BallTrack): after download, generate per-match frame/<rally>/ (JPG frames) and median.npz from the videos using DataPreprocess/extract_frames.py and DataPreprocess/create_median.py. These are omitted from the Hub release to save space; see the project README.
csv/<rally>_ball.csv)
| Column | Type | Description |
|---|---|---|
| Frame | int | 0-indexed frame number |
| X | int | Ball center X in pixels (1920×1080) |
| Y | int | Ball center Y in pixels |
| Visibility | int | 1 = visible, 0 = not visible |
racket/<rally>/<frame_id>.json)
Per-frame JSON with a list of racket instances, each containing:
{
"category": "badminton_racket",
"bbox_xywh": [x, y, w, h],
"keypoints": [[x1, y1, vis], [x2, y2, vis], ...]
}
5 keypoints are defined: top, bottom, handle, left, right.
info/*_coco.json)
Standard COCO format used by RacketPose for training/evaluation:
*_det_coco.json): 3 categories — badminton_racket, tabletennis_racket, tennis_racket.*_pose_coco.json): 1 category (racket) with 5 keypoints.data_traj/*.pkl)
Pickle files containing pre-processed sliding-window samples. Each PKL has:
{
'train_samples': [...], # List of sample dicts
'test_samples': [...],
'train_dataset': ..., # Legacy Dataset objects
'test_dataset': ...,
'metadata': {
'history_len': 80,
'future_len': 20,
'sports': ['badminton'],
'total_samples': N,
'train_size': ...,
'test_size': ...
}
}
Each sample dict:
{
'history': np.array(shape=(H, 2)), # Normalised [X, Y] in [0, 1]
'future': np.array(shape=(F, 2)),
'history_rkt': np.array(shape=(H, 10)), # 5 keypoints × 2 coords, normalised
'future_rkt': np.array(shape=(F, 10)),
'sport': str,
'match': str,
'sequence': str,
'start_frame': int
}
Normalisation: Ball coordinates are divided by (1920, 1080). Racket keypoints are divided by the same values.
<sport>/info/train.json)
JSON list of [match_id, rally_id] pairs:
[["match1", "000"], ["match1", "001"], ...]
If you have the raw videos, use DataPreprocess/ scripts in the code repository to prepare all intermediate files:
cd DataPreprocess
# 1. Extract video frames to JPG
python extract_frames.py --data_root ../data --sport badminton
# 2. Compute median background frame
python create_median.py --data_root ../data --sport badminton
# 3. Generate dataset_info.json and per-sport split files
python generate_dataset_info.py --data_root ../data
# 4. Generate COCO annotations for RacketPose
python generate_coco_annotations.py --data_root ../data
After running BallTrack and RacketPose inference, build data_traj/ PKLs:
cd TrajPred
# Interpolate short gaps in ball predictions
python linear_interpolate_ball_traj.py --data_root ../data --sport badminton
# Merge racket predictions with ground truth annotations
python merge_gt_with_predictions.py --data_root ../data --sport badminton
# Build PKL dataset
python build_dataset.py --data_root ../data --sport badminton --history 80 --future 20
If you find this work useful, please consider citing:
@inproceedings{dong2026racket,
title={Racket Vision: A Multiple Racket Sports Benchmark for Unified Ball and Racket Analysis},
author={Dong, Linfeng and Yang, Yuchen and Wu, Hao and Wang, Wei and Hou, Yuenan and Zhong, Zhihang and Sun, Xiao},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence (AAAI)},
year={2026}
}